
Временные ряды в эконометрических исследованиях
Модели, построенные по данным, характеризующим один объект за ряд последовательных моментов (периодов), называются моделями временных рядов.
Временной ряд — это совокупность значений какого-либо показателя за несколько последовательных моментов или периодов.
Каждый уровень временного ряда формируется из трендовой 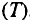
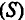
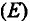
Модели, в которых временной ряд представлен как сумма перечисленных компонент, — аддитивные модели, как произведение -мультипликативные модели временного ряда. Аддитивная модель имеет вид:
мультипликативная модель:
Построение аддитивной и мультипликативной моделей сводится к расчету значений 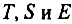
1) выравнивание исходного ряда методом скользящей средней;
2) расчет значений сезонной компоненты 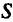
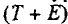
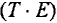
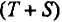
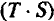
6) расчет абсолютных и/или относительных ошибок.
Автокорреляция уровней ряда — это корреляционная зависимость между последовательными уровнями временного ряда:
где
коэффициент автокорреляции уровней ряда первого порядка;
где
коэффициент автокорреляции уровней ряда второго порядка.
Формулы для расчета коэффициентов автокорреляции старших порядков легко получить из формулы линейного коэффициента корреляции.
Последовательность коэффициентов автокорреляции уровней первого, второго и т.д. порядков называют автокорреляционной функцией временного ряда, а график зависимости ее значений от величины лага (порядка коэффициента автокорреляции) — коррело-граммой.
Построение аналитической функции для моделирования тенденции (тренда) временного ряда называют аналитическим выравниванием временного ряда. Для этого чаще всего применяются следующие функции:
• линейная 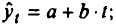
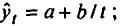
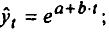
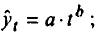
• парабола второго и более высоких порядков
Параметры трендов определяются обычным МНК, в качестве независимой переменной выступает время 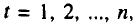
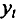
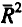
При построении моделей регрессии по временным рядам для устранения тенденции используются следующие методы.
Метод отклонений от тренда предполагает вычисление трендовых значений для каждого временного ряда модели, например 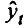
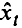
Для дальнейшего анализа используют не исходные данные, а отклонения от тренда.
Метод последовательных разностей заключается в следующем: если ряд содержит линейный тренд, тогда исходные данные заменяются первыми разностями:
если параболический тренд — вторыми разностями:
В случае экспоненциального и степенного тренда метод последовательных разностей применяется к логарифмам исходных данных.
Модель, включающая фактор времени, имеет вид
Параметры а и b этой модели определяются обычным МНК.
Автокорреляция в остатках — корреляционная зависимость между значениями остатков 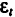
Для определения автокорреляции остатков используют критерий Дарвина — Уотсона и расчет величины:
Коэффициент автокорреляции остатков первого порядка определяется по формуле
Критерий Дарбина — Уотсона и коэффициент автокорреляции остатков первого порядка связаны соотношением
Эконометрические модели, содержащие не только текущие, но и лаговые значения факторных переменных, называются моделями с распределенным лагом.
Модель с распределенным лагом в предположении, что максимальная величина лага конечна, имеет вид
Коэффициент регрессии 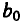
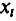
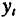
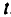
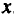
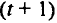
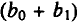
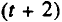
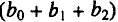

Величины
называются относительными коэффициентами модели с распределенным лагом. Если все коэффициенты 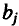
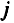
Величина среднего лага модели множественной регрессии определяется по формуле средней арифметической взвешенной:
и представляет собой средний период, в течение которого будет происходить изменение результата под воздействием изменения фактора в момент 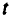
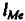
Оценку параметров моделей с распределенными лагами можно проводить согласно одному из двух методов: методу Койка или методу Алмон.
В распределении Койка делается предположение, что коэффициенты при лаговых значениях объясняющей переменной убывают в геометрической прогрессии:
Уравнение регрессии преобразуется к виду
После несложных преобразований получаем уравнение, оценки параметров которого приводят к оценкам параметров исходного уравнения.
В методе Алмон предполагается, что веса текущих и лаговых значений объясняющих переменных подчиняются полиномиальному распределению:
Уравнение регрессии примет вид
Расчет параметров модели с распределенным лагом методом Алмон проводится по следующей схеме:
1) устанавливается максимальная величина лага 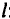
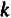
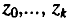
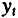
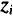
5) рассчитываются параметры исходной модели с распределенным лагом.
Модели, содержащие в качестве факторов лаговые значения зависимой переменной, называются моделями авторегрессии, например:
Как и в модели с распределенным лагом, 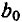
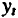
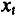
Отметим, что такая интерпретация коэффициентов модели авторегрессии и расчет долгосрочного мультипликатора основаны на предпосылке о наличии бесконечного лага в воздействии текущего значения зависимой переменной на ее будущие значения.
Парная регрессия и корреляция
Парная регрессия — уравнение связи двух переменных 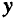
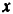
Различают линейные и нелинейные регрессии.
Линейная регрессия : 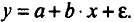
Нелинейные регрессии делятся на два класса: регрессии, нелинейные относительно включенных в анализ объясняющих переменных, но линейные по оцениваемым параметрам, и регрессии, нелинейные по оцениваемым параметрам.
Возможно эта страница вам будет полезна:
Регрессии, нелинейные по объясняющим переменным:
• полиномы разных степеней 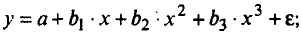
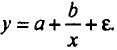
Регрессии, нелинейные по оцениваемым параметрам’.
• степенная 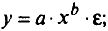
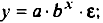
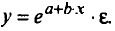
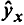
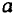
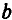
Можно воспользоваться готовыми формулами, которые вытекают из этой системы:
Тесноту связи изучаемых явлений оценивает линейный коэффициент парной корреляции 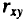
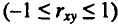
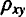
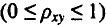
Оценку качества построенной модели даст коэффициент (индекс) детерминации, а также средняя ошибка аппроксимации.
Средняя ошибка аппроксимации — среднее отклонение расчетных значений от фактических:
Допустимый предел значений 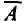
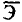
Задача дисперсионного анализа состоит в анализе дисперсии зависимой переменной:
где 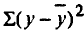
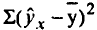
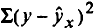
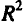
Коэффициент детерминации — квадрат коэффициента или индекса корреляции.
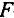
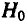
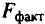
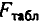
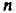
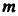
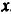
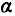
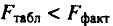
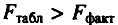 Для оценки статистической значимости коэффициентов регрессии и корреляции рассчитываются
Для оценки статистической значимости коэффициентов регрессии и корреляции рассчитываются 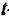 -критерий Стьюдента и доверительные интервалы каждого из показателей. Выдвигается гипотеза о случайной природе показателей, т.е. о незначимом их отличии от нуля. Оценка значимости коэффициентов регрессии и корреляции с помощью -критерия Стьюдента проводится путем сопоставления их значений с величиной случайной ошибки:
-критерий Стьюдента и доверительные интервалы каждого из показателей. Выдвигается гипотеза о случайной природе показателей, т.е. о незначимом их отличии от нуля. Оценка значимости коэффициентов регрессии и корреляции с помощью -критерия Стьюдента проводится путем сопоставления их значений с величиной случайной ошибки:
Случайные ошибки параметров линейной регрессии и коэффициента корреляции определяются по формулам:
Сравнивая фактическое и критическое (табличное) значения 
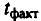
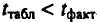
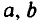
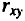
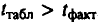
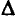
Формулы для расчета доверительных интервалов имеют следующий вид:
Если в границы доверительного интервала попадает ноль, т.е. нижняя граница отрицательна, а верхняя положительна, то оцениваемый параметр принимается нулевым, так как он не может одновременно принимать и положительное, и отрицательное значения.
Прогнозное значение 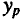
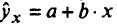
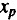
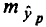
где
Реализация типовых задач в excel
- Решение примера проведем с использованием ППП MS Excel и Statgraphics.
Решение с помощью ППП Excel
Сводную таблицу основных статистических характеристик для одного или нескольких массивов данных можно получить с помощью инструмента анализа данных Описательная статистика. Для этого выполните следующие шаги:
1) введите исходные данные или откройте существующий файл, содержащий анализируемые данные;
2) в главном меню выберите последовательно пункты Сервис / Анализ данных / Описательная статистика, после чего щелкните по кнопке ОК;
3) заполните диалоговое окно ввода данных и параметров вывода (рис. 2.1):
Входной интервал — диапазон, содержащий анализируемые данные, это может быть одна или несколько строк (столбцов); Группирование — по столбцам или по строкам — необходимо указать дополнительно;
Метки — флажок, который указывает, содержит ли первая строка названия столбцов или нет;
Выходной интервал — достаточно указать левую верхнюю ячейку будущего диапазона;
Новый рабочий лист — можно задать произвольное имя нового листа.
Если необходимо получить дополнительную информацию Итоговой статистики, Уровня надежности, k-го наибольшего и наименьшего значений, установите соответствующие флажки в диалоговом окне. Щелкните по кнопке ОК.
Результаты вычисления соответствующих показателей для каждого признака представлены на рис. 2.2.
Решение с помощью ППП Statgraphics
Для проведения многофакторного анализа в ППП Statgraphics используется пункт меню Multiple Variable Analysis. Для получения показателей описательной статистики необходимо проделать следующие операции:
1) ввести исходные данные или открыть существующий файл, содержащий анализируемые данные;
2) в главном меню выбрать Describe/Numeric Data/Multiple Variable Analysis;
3) заполнить диалоговое окно ввода данных (рис. 2.3). Ввести названия всех столбцов, значения которых вы хотите включить в анализ; щелкнуть по кнопке ОК;
4) в окне табличных настроек поставить флажок напротив Summary Statistics (рис. 2.4). Итоговая статистика — показатели вариации -появится в отдельном окне.
Для данных примера 4 результат применения функции Multiple Variable Analysis представлен на рис. 2.5.
Сравнивая значения средних квадратических отклонений и средних величин и определяя коэффициенты вариации:
приходим к выводу о повышенном уровне варьирования признаков, хотя и в допустимых пределах, не превышающих 35%. Совокупность предприятий однородна, и для ее изучения могут использоваться метод наименьших квадратов и вероятностные методы оценки статистических гипотез.
- Значения линейных коэффициентов парной корреляции определяют тесноту попарно связанных переменных, использованных в данном уравнении множественной регрессии. Линейные коэффициенты частной корреляции оценивают тесноту связи значений двух переменных, исключая влияние всех других переменных, представленных в уравнении множественной регрессии.
Решение с помощью ППП Excel
К сожалению, в ППП MS Excel нет специального инструмента для расчета линейных коэффициентов частной корреляции. Матрицу парных коэффициентов корреляции переменных можно рассчитать, используя инструмент анализа данных Корреляция. Для этого:
1) в главном меню последовательно выберите пункты Сервис / Анализ данных / Корреляция. Щелкните по кнопке ОК;
2) заполните диалоговое окно ввода данных и параметров вывода (см. рис. 2.1);
3) результаты вычислений — матрица коэффициентов парной корреляции — представлены на рис. 2.6.
Решение с помощью ППП Stat graphics
При проведении многофакторного анализа — Multiple Variable Analysis — вычисляются линейные коэффициенты парной корреляции и линейные коэффициенты частной корреляции. Последовательность операций описана в п.1 этого примера. Для отображения результатов вычисления на экране необходимо установить флажки напротив Correlations и Partial Correlations в окне табличных настроек (рис. 2.7).
В результате получим матрицы коэффициентов парной и частной корреляции (рис. 2.8).
Значения коэффициентов парной корреляции указывают на весьма тесную связь выработки у как с коэффициентом обновления основных фондов — 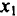
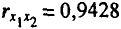
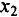
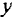 Коэффициенты частной корреляции дают более точную характеристику тесноты связи двух признаков, чем коэффициенты парной корреляции, так как очищают парную зависимость от взаимодействия данной пары признаков с другими признаками, представленными в модели. Наиболее тесно связаны и : связь
Коэффициенты частной корреляции дают более точную характеристику тесноты связи двух признаков, чем коэффициенты парной корреляции, так как очищают парную зависимость от взаимодействия данной пары признаков с другими признаками, представленными в модели. Наиболее тесно связаны и : связь
Если сравнить коэффициенты парной и частной корреляции, то можно увидеть, что из-за высокой межфакторной зависимости коэффициенты парной корреляции дают завышенные оценки тесноты связи:
Именно по этой причине рекомендуется при наличии сильной коллинеарности (взаимосвязи) факторов исключать из исследования тот фактор, у которого теснота парной зависимости меньше, чем теснота межфакторной связи.
- Вычисление параметров линейного уравнения множественной регрессии.
Решение с помощью ППП Excel
Эта операция проводится с помощью инструмента анализа данных Регрессия. Она аналогична расчету параметров парной линейной регрессии, описанной в 1-м разделе практикума, только в отличие от парной регрессии в диалоговом окне при заполнении параметра входной интервал и следует указать не один столбец, а все столбцы, содержащие значения факторных признаков. Результаты анализа представлены на рис. 2.9.
Для вычисления параметров множестнсшшП регрессии можно использовать процедуру Multiple Regression. Дни »нно:
1) введите исходные данные или откройте сущее i иун>щи11 файл;
2) в главном меню последовательно выберите Heinle / Multiple Regression;
3) заполните диалоговое окно ввода данных. II ноне Depended Variable введите название столбца, содержащею шичпш» зависимой переменной, в поле Independed Variable — нашими* i ишбцов, содержащих значения факторов. Щелкните по кнопке ОК
Результаты вычисления функции Multiple КсЦ1 гм1«ш появятся в отдельном окне (рис. 2.10).
По результатам вычислений составим урцниемн* множественной регрессии вида
Значения случайных ошибок параметров 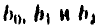
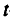
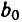
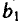
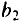
На это же указывает показатель вероятности случайных значений параметров регрессии: если а меньше принятого нами уровня (обычно 0,1; 0,05 или 0,01; это соответствует 10%; 5% или 1% вероятности), делают вывод о неслучайной природе данного значения параметра, т.е. о том, что он статистически значим и надежен. В противном случае принимается гипотеза о случайной природе значения коэффициентов уравнения. Здесь
что позволяет рассматривать 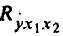
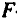
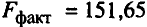
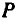
Значения скорректированного и нескорремирпианпого линейных коэффициентов множественной детерминации приведены на рис. 2.9 и 2.10 в рамках регрессионной статистики.
Нескорректированный коэффициент множественной детерминации
оценивает долю вариации результата за счет представленных в уравнении фактором в общей вариации результата. Здесь эта доля составляет 94,7% и указывает на весьма высокую степень обусловленности вариации вариацией факторов, иными словами — на весьма теси> i факторов с результатом.
Скорректированный коэффициент множественной детерминации
определяет тесноту связи с учетом степеней свободы общей и остаточной дисперсий. Он дает такую оценку тесноты связи, которая не зависит от числа факторов и потому может сравниваться по разным моделям с разным что ном факторов. Оба коэффициента указывают на весьма высокую (Ооиес 90%) детерминированность результата в модели факторами.
1) введите исходные данные или откройте существующий файл;
2) в главном меню последовательно выберите пункты Relate / Multiple Regression;
3) заполните диалоговое окно ввода данных. В поле Depended Variable введите название столбца, содержащего значения зависимой переменной, в поле Independed Variable — названия столбцов, содержащих значения факторов, в том порядке, в котором будет проводиться анализ целесообразности включения факторов в модель. Чтобы оценить статистическую значимость включения в модель фактора
4) в окне табличных настроек поставьте флажок напротив поля Conditional Sums of Squares.
Результаты вычисления показаны на рис. 2.11.
Частный 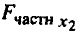
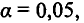 Если поменять первоначальный порядок включения факторов в модель и рассмотреть вариант включения после , то результат расчета частного -критерия для будет иным. Вероятность его случайного формирования составила 0,04%, это значительно меньше принятого стандарта
Если поменять первоначальный порядок включения факторов в модель и рассмотреть вариант включения после , то результат расчета частного -критерия для будет иным. Вероятность его случайного формирования составила 0,04%, это значительно меньше принятого стандарта
более простым, хорошо детерминированным, ириголным для анализа и для прогноза.
- Средние частные коэффициенты эластичности показывают, на сколько процентов от значения своей средней изменяется результат при изменении фактора на 1% от своей средней и
при фиксированном воздействии на у всех прочих факторов, включенных в уравнение регрессии. Для линейной зависимости
где 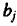
Возможно эта страница вам будет полезна:






